- Dansk
-
EnglishDeutschItaliaFrançais한국의русскийSvenskaNederlandespañolPortuguêspolski繁体中文SuomiGaeilgeSlovenskáSlovenijaČeštinaMelayuMagyarországHrvatskaDanskromânescIndonesiaΕλλάδαБългарски езикGalegolietuviųMaoriRepublika e ShqipërisëالعربيةአማርኛAzərbaycanEesti VabariikEuskeraБеларусьLëtzebuergeschAyitiAfrikaansBosnaíslenskaCambodiaမြန်မာМонголулсМакедонскиmalaɡasʲພາສາລາວKurdîსაქართველოIsiXhosaفارسیisiZuluPilipinoසිංහලTürk diliTiếng ViệtहिंदीТоҷикӣاردوภาษาไทยO'zbekKongeriketবাংলা ভাষারChicheŵaSamoa日本語SesothoCрпскиKiswahiliУкраїнаनेपालीעִבְרִיתپښتوКыргыз тилиҚазақшаCatalàCorsaLatviešuHausaગુજરાતીಕನ್ನಡkannaḍaमराठी
Xilinx FPGA programmering og Vivado designflow forklaret
Katalog

Udforskning af Xilinx FPGA-tutorials
At arbejde med FPGAs kan i starten føles mentalt tungere end software, delvist fordi målet ikke er at udføre instruktioner, men at beskrive hardwarestrukturer, der kører samtidig. Man ender med at tænke på samtidighed, clocking-regler, resetadfærd og om tidsrapporter stemmer overens med det, man troede, man havde bygget. Når folk bliver frustrerede tidligt, er det ofte ikke fordi, de mangler indsats, men fordi alt for mange bevægelige dele ændrer sig mellem forsøg, og årsagen til fejl bliver besværligt glat.
En stabil vej frem er at gentage det samme arbejdsflow, indtil det bliver så bekendt, at fejl skiller sig ud. Hold en godt understøttet Xilinx-board på dit skrivebord, start med et lille HDL-design, simuler det, indtil bølgeskemaerne giver mening, kør syntese og implementering i Vivado, programmer enheden, og bekræft derefter adfærden på rigtige ben. Selvom denne proces kan virke gentagende, hjælper det med at reducere usikkerheden om, hvorvidt et problem skyldes designkoden, begrænsningerne eller boardkonfigurationen, hvilket gør fejlfinding mere effektiv.
I dag-til-dag læring klumper den stejleste del af kurven sig typisk omkring et par færdigheder, der forstærker hinanden: at bruge Vivados flow med disciplin, skrive synthesizable Verilog, der kortlægger på den måde, du forventer, og fejlfinde de uundgåelige huller mellem simulering og det fysiske board med en metode, du stoler på. Hvis du behandler hver opbygning som et kontrolleret eksperiment, ændrer en variabel, observerer effekten og skriver ned, hvad du så, vil du bemærke, at du bruger mindre tid på at gætte og mere tid på at danne pålidelige instinkter.
Brug Vivados projektflow på en måde, der forbliver stabil over tid
Vivado opfører sig mindre som en simpel kompileringsknap og mere som en pipeline, der omsætter RTL til et placeret og routet design, der skal leve inden for boardets elektriske og tidsmæssige realiteter. Mange begyndere opdager, nogle gange den hårde vej, at meget af korrektheden lever uden for HDL: begrænsninger, clock-definitioner, I/O-standarder og værktøjsindstillinger kan stille og roligt afgøre, om hardwaren opfører sig, som simuleringen lovede.
Et rent flow starter med at holde projektopsætningen beskeden og gentagelig, så du kan fortælle, hvornår du virkelig har forbedret designet i forhold til, hvornår du ved et uheld har ændret miljøet.
Vælg et understøttet board og bliv ved det længe nok til at opbygge en intuition, du kan genbruge. Boards med solid dokumentation og referencedesigns har tendens til at reducere den bagvedliggende angst, fordi du kan krydstjekke dit pinout, clocks og strømantagelser uden at lede efter uofficielle forumindlæg.
Start med et topmodul, der hurtigt producerer et synligt resultat. Den umiddelbare feedback hjælper dig med at validere, at clocken kører, pins er kortlagt korrekt, og bitstreams genereres på den måde, du tror, de gør.
Eksempler på observerbar topniveauadfærd:
• Et blinkende LED
• En UART-echo
• En tæller, der driver GPIO
En praktisk vane er at standardisere en lille topniveau skabelon tidligt. For eksempel, hold en klokkeindgang, en nulstilling tilgang du forstår, og en lille, konsistent GPIO bundle. Når stilladset forbliver det samme fra projekt til projekt, kan du fokusere din opmærksomhed på den nye logik i stedet for at genaflede grundlæggende, hver gang, noget der kan føles kedeligt og overraskende fejlbehæftet.
Begrænsninger er en kernekomponent i FPGA-design snarere end et sidste justeringstrin. Mange tidlige hardwareproblemer opstår selv når RTL-designet er korrekt, fordi klokkebegrænsninger mangler eller er forkerte, ben er tildelt forkert, eller I/O-standarder matcher ikke de faktiske bræddekrafter.
En konkret arbejdsgang, der holder dig ærlig, er at definere clock i XDC, kortlægge porte ved hjælp af leverandørens master XDC som reference, og derefter verificere I/O-standarder mod kredsskematikken. Den proces kan føles lidt bureaukratisk i starten, men den har tendens til at erstatte vag mistanke med kontrollerbare fakta.
Timinglukning er heller ikke reserveret til hurtige designs. Selv logik der ser langsom ud på papir, kan opføre sig dårligt, hvis værktøjet udleder utilsigtede clock-forhold, eller hvis asynkrone signaler håndteres tilfældigt. At blive komfortabel med at læse timingrapporter tidligt kan reducere den ubehagelige følelse af “jeg håber, dette er fint”, når designene bliver større.
Vivado fortæller konstant dig, hvad det mener om dit design; den smertefulde del er, at det er let at klikke forbi advarslerne og så bruge timer på at fejlfinde et problem, der allerede blev beskrevet på konsollen. Over tid er de mennesker, der bevæger sig hurtigere, ofte dem, der bygger en rolig vane med at tjekke rapporter efter hver kørsel, selv når de forventer, at alt er fint.
Efter hver syntese/implementering kørsel, hold disse rapportkategorier sammen på deres egen tjekliste linje:
• Timingstatus og kritiske stier
• Ressourceudnyttelse (LUT/FF/BRAM/DSP) versus forventninger
• Inferensresultater (for RAM, DSP blokke, og andre tilsigtede strukturer)
Når en advarsel har været til stede siden den første opbygning, har den tendens til at fortsætte med at dukke op i de mærkeligste fejl senere. En produktiv holdning er at antage, at advarsler fortjener opmærksomhed, indtil du kan forklare, i klare ingeniørtermer, hvorfor de er ufarlige for dit specifikke design.
Skriv syntetiserbar Verilog der kortlægger rent til FPGA-hardware
HDL-arbejde er tættere på kredsløbsdesign end app-udvikling, og det skift kan være følelsesmæssigt forstyrrende: du kan skrive gyldig Verilog der simulerer smukt, men alligevel syntetiserer til noget langsommere, større, eller simpelthen anderledes end du forestillede dig. Målet er at beskrive strukturer, som FPGA'en kan implementere forudsigeligt: flip-flops, LUT-logik, BRAM, og DSP-blokke, så adfærd og timing stemmer overens med din hensigt.
Når kortlægningen er forudsigelig, føles fejlfinde mindre som at diskutere med værktøjet og mere som at forfine et design.
En komfortabel baseline for mange begyndere er et enkelt clock domæne med ligetil synkron logik. Brug clocked always blokke til sekventiel tilstand og kontinuerlige tildelinger (eller korrekt skrevne kombinationsblokke) til kombinationsveje. At skabe “clock-lignende” logik i fabric kan fungere i niche tilfælde, men det har tendens til at invitere clock-domænerisici med mindre du allerede forstår clock gating, routing, og timingimplikationer.
Nulstillingsadfærd er et andet sted, hvor små valg kan skabe overraskende inkonsistente brædderesultater. Asynkrone nulstillinger kan være nyttige, men de kan også producere deaktiveringsfarer eller følsomhed over for brædderniveauer strømforskel. Mange FPGA-design bruger fuldt synkroniserede nulstillinger eller asynkron påstand med synkron frigørelse, fordi disse tilgange hjælper med at reducere inkonsistent opstartadfærd under opstartsprøvning.
FPGA-logik læner sig naturligt op ad pipelines og parallelle strukturer. En almindelig begynderskuffelse er at forvente softwarelignende trin-for-trin udførelse, og derefter føle sig forvirret, når alt sker på én gang. En mere nyttig linse er at beslutte, hvad du værdsætter for en given blok og derefter designe eksplicit for det resultat.
En enkelt linje designlinse for ydeevne og kortlægning:
• Gennemløb (varer pr. clock)
• Latens (cykler fra input til output)
• Ressourcemapping præference (LUT'er vs BRAM vs DSP)
For eksempel kan en multiplkation-akkumulation lede DSP-skiver rent, men mindre ændringer i kodestil kan skubbe værktøjet mod LUT-baseret aritmetik. Når udnyttelse overrasker dig, er det ofte værd at tage en pause og stille et lidt ubehageligt spørgsmål: beskrev du faktisk den hardwarestruktur, du havde i tankerne, eller beskrev du noget funktionelt ækvivalent, der koster flere ressourcer?
Simulation vil gerne acceptere konstruktioner, som virkelig hardware ikke kan implementere på den måde, du måtte forestille dig. At holde din syntetiserbare grænse klar reducerer falsk selvtillid og gør simuleringsresultater mere bærbare til brættet.
Almindelige mønstre at holde grupperet på én linje som en hurtig påmindelse:
• Undgå forsinkelser (#) i synthesizable logik
• Afhæng ikke af initialisering, medmindre du har bekræftet enhedens/værktøjets adfærd
• Hold øje med utilsigtede latch ved ufuldstændige kombinationstildelinger
• Brug passende synkronisatorer til clock-domain overgange
En vane, der tendere til at betale sig, er at skrive små selvkontrollerende testbenches, der validerer de antagelser, du følelsesmæssigt fristes til at overskride: resetadfærd, tæller rollover, håndtryksprotokoller og hjørnbetingelser. Når projekter vokser, bliver disse tests mindre som ekstra arbejde og mere som det, der forhindrer dig i at overveje alt på ny.
Debug systematisk med simulering og on-chip synlighed (ILA)
Selv fremragende simulering lover ikke korrekt brædeadfærd. Rigtig hardware bringer clock jitter, I/O-forsinkelser, uklare initialtilstande, og asynkrone inddata, der ikke venligt tilpasser sig din clock kant. De hurtigste debuggers er normalt ikke dem, der laver tilfældige redigeringer, de er dem, der indsnævrer problemet med struktureret observation og kan forklare, hvilket bevis der ændrede deres mening.
En stærk testbench tjekker adfærd over mange cyklusser og undgår ikke ubehagelige scenarier. Hvis du modellerer realistisk stimulus, bliver simuleringen et sted, hvor du opbygger tillid, ikke bare et sted, hvor du ser et signal skifte og håber, det betyder noget.
Realistiske stimuli, der har tendens til at afsløre skrøbelig logik:
• Knappens bounce
• UART framing fejl
• Backpressure i streaming interfaces
• Reset sekvenser med akavet timing
Det hjælper også at adskille fejl i to kategorier, så du ikke jagter den forkerte slags løsning:
• Funktionelle fejl: RTL's logik er forkert
• Integrationsfejl: RTL er fint, men clocks/resets/constraints/I/O antagelser er forkerte
Simulering er fremragende til at presse funktionelle fejl ud; bræddeforsøg har en måde at afsløre integrationsfejl, du ikke ville tro var mulige.
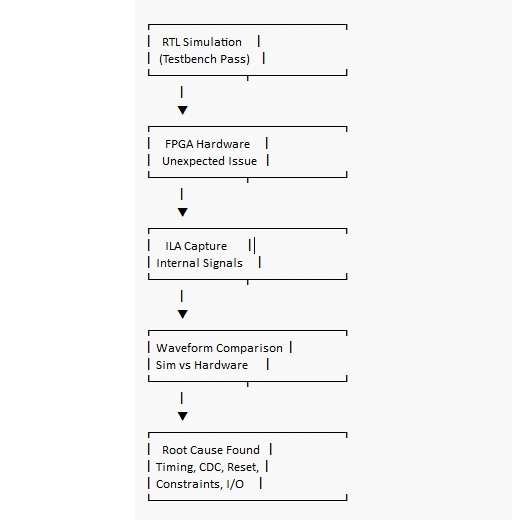
Når hardwareadfærd ikke stemmer overens med din testbench, er den integrerede logikanalysator (ILA) ofte den mest direkte måde at erstatte spekulation med en spor, du kan studere. Undersøg signaler, der repræsenterer beslutninger og grænser inde i designet, og fang derefter øjeblikket, hvor tingene divergerer, og sammenlign det med den forventede simuleringsbølgeform.
Signaler, der har tendens til at være højt værdi probes:
• FSM tilstands kodninger
• valid/ready håndtryk
• FIFO fuld/tom flag
• reset synkronisatorudgange
En praktisk arbejdsgang er at starte med færre probings og et bredere fangvindue. Efterhånden som du lærer, hvor fejlen bor, kan du stramme udløseren og tilføje detaljer. Over-instrumentering kan reducere timing-margin og komplicere builds, så det er ofte sundere at betragte ILA-insertion som et fokuseret måleskridt snarere end noget, du holder for en sikkerheds skyld.
Nogle af de mest undervisende fejl sker, når simuleringen ser fejlfri ud, og brættet er ustabilt. Den mismatch kan føles nedslående, men det er også her FPGA-intuitionen bliver skarpere, fordi løsningen normalt ligger i clocking, constraints, eller signald
Almindelige årsager til simulering/bræt divergence:
• Manglende eller forkert clock constraints
• Metastabilitet fra usynkroniserede input
• Reset frigivelsestiming variation på tværs af chippen
• CDC problemer mellem flere clock domæner
• Forskelle i initiale betingelser
Et perspektiv, der har tendens til at accelerere læring, er at betragte timing og observabilitet som egenskaber, du bevidst indbygger i designet. Når dine små projekter eksplicit definerer clocks, begrænser I/O, synkroniserer overgange, og eksponerer interne signaler for måling, bruger du mindre tid på at håbe, det virker, og mere tid på at lave kontrollerede, forklarlige forbedringer. Den tankegang skalerer naturligt fra en blinkende LED til større pipelines, interfaces, og indlejrede systemer på den samme enhed.
Xilinx (AMD) vs. Altera (Intel) FPG
Xilinx (AMD) og Intel (Altera) leverer begge FPGA-familier, der ser sammenlignelige ud på papiret, og det er nemt at føle sig sikker efter et hurtigt datasheet scan. Stemningen har tendens til at ændre sig senere, når dag-til-dag ingeniørrealiteter begynder at bestemme tempoet: værktøjets adfærd på din præcise enhed og hastighedsgrad, om IP, du antog, du kunne bruge, faktisk er licensieret i din organisation, om et reference design virkelig stemmer overens med dine clocks og resets, og om timing lukning forbliver stabil, når designet bliver produktionsklar.
En udvælgelsesproces holder sig bedre oppe, når du betragter FPGA'en som et leveringssystem, enhed + værktøjer + IP + brædder + dokumentation + langsigtet vedligeholdelse, fordi det er her, hold enten får momentum (og søvn) eller akkumulerer stille tidsplanangst.
| Funktion |
Xilinx (AMD) |
Intel (Altera) |
| Markedsposition |
Historisk set markedsleder, kendt for bred produktportefølje og at være først på markedet med nye teknologier. |
Stærk konkurrent, især stærk inden for data center og netværksapplikationer, der udnytter Intels fremstillingskompetence. |
| Kernearkitektur |
Logik er primært baseret på 6-input Look-Up Tabellen (LUTs), der tilbyder høj granularitet og fleksibilitet. |
Bruger Adaptive Logic Modules (ALMs), som er mere komplekse og kan konfigureres som større LUTs, hvilket potentielt forbedrer logic densitet for visse design. |
| Software Suite |
Vivado Design Suite og Vitis Unified Software Platform. Ofte rost for sin brugervenlige grænseflade for erfarne udviklere. |
Quartus Prime Design Suite. Nogle brugere finder, at dens GUI er mere intuitiv for begyndere, og det er kendt for hurtigere kompileringstider i nogle scenarier. |
| High-End Familiers |
Versal ACAPs (Adaptive Compute Acceleration Platforms), der kombinerer skalar, tilpasningsdygtige og intelligente motorer. |
Agilex FPGAs, kendt for høj ydeevne og energieffektivitet, med nogle benchmarks, der viser en ydeevne-per-watt fordel. |
| Økosystemfokus |
Stærkt fokus på at integrere processor og FPGA, som set i Zynq-familien. Populær til applikationsudvikling. |
Velkendt til System-on-Chip design og industrielle applikationer, med en stærk IP-portefølje til netværk og RF. |
Definer valg ved hjælp af verifiable begrænsninger, ikke brandforventninger
Start med krav, du kan teste tidligt, ikke indtryk fra tidligere projekter. Målet er at reducere "overraskelser i uge 10", som er, hvor frustration og omarbejde plejer at hobe sig op.
Checkliste til begrænsninger:
• Logikressourcer: LUTs/ALMs, registre, tilgængelighed af routing og forventet udnyttelsesloft
• DSP-ressourcer: blokantal, præcisionsmuligheder, pre-adders, kaskade/topologi muligheder og mapping adfærd for dine matematiske kerner
• On-chip hukommelse: BRAM/URAM (eller M20K ækvivalenter), samlet kapacitet, porttilstande, båndbredde pr. klokke og kontentionsmønstre
• Højteknologisk I/O: SERDES klasse, lanesantal, maksimal linjehastighed, referenceklokke muligheder og protokol understøttelse knyttet til dit brugsscenarie
• Ekstern hukommelse: DDR3/DDR4/LPDDR varianter, controller modenhed, kalibreringsadfærd og SI-margin for antagelser
• Latens og determinisme: end-to-end mål, budget pr. trin, jitter tolerans og CDC strategi (inklusive hvordan resets krydser domæner)
• Effekt/termisk envelope: worst-case switching skøn, transceiver power modes, heatsinking antagelser og omgivende rækkevidde
Ægte FPGA-projekter viser ofte, at at passe ind i enheden ikke garanterer pålidelig højhastighedsdrift. Design, der ser acceptable ud ved 70–80% udnyttelse, kan blive ustabile efter at have tilføjet debug logik, CDC-beskyttelse, FIFOs, fejlbehandling og timing-margin, der er nødvendig for praktisk drift.
Hvis dit team nogensinde har mistet en uge på routing overbelastning whack-a-mole, er tiltrækningen ved at opgradere én enheds størrelse let at forstå. Omkostningshandlen er normalt ikke linear: en lidt større del kan købe roligere timing, færre værktøjsiterationer og færre sene nat rebygninger.
Behandl værktøjsflow som et krav, du ikke kan ønske væk
Værktøjsflow plejer at være den skjulte separator mellem en plan, der ser solid ud, og en plan, der bliver ved med at glide. Folk undervurderer ofte, hvor meget følelsesmæssig båndbredde der bliver forbrugt på langsomme eller uforudsigelige iterationer, især når en byggeproces tager timer, og fejltilstanden er vag.
Checkliste til vurdering af værktøjsflow:
• Iterationshastighed: syntese + placering/routing + bitstream tid på dit CI-hardware, ikke en leverandørdemomaskine
• Timing lukningsadfærd: QoR trends, stabilitet på tværs af frø og følsomhed over for små ændringer i begrænsninger
• Begrænsninger og observabilitet: SDC/XDC klarhed, klokke modeling nøjagtighed, false-path/multicycle håndtering, og hvor debuggable overtrædelser er
• Debug instrumentering: logikanalysator indsætningsflow, probe fleksibilitet, trigger dybde og hvor ofte du skal recompile for at observere signaler
• Miljøtilpasning: understøttede OS-versioner, headless builds, licensfriktion og hvor godt det matcher dit teams arbejdsgang
• CI/VCS venlighed: reproducerbarhed, deterministiske output (så meget som værktøjerne tillader), scriptbarhed og opgraderingsbesvær
Før du forpligter dig, kør en timing-lukkeprøve på noget repræsentativt (ikke et legetøj). Inkluder dine rigtige klokker, mindst én ekstern hukommelsesgrænseflade og mindst én højteknologisk I/O blok. Spor:
• Vægklokke kompileringstid pr. iteration
• Slack stabilitet på tværs af nogle frø
• Hvor hurtigt en ingeniør kan diagnosticere de første tre timingproblemer uden stammeviden
Det eksperiment har en tendens til at producere en form for klarhed, som funktionstjeklister ikke gør. Det afslører også, om dit team vil føle sig stabilt eller konstant anspændt i integrationsfasen.
IP-tilgængelighed og licensering: Hvor tidsplaner ofte strammer til
Selv når rå FPGA-ressourcer ser ens ud, afhænger tidsplaner ofte af IP-realiteter. Det er her, teamene kan føle sig blindsided: kernen eksisterer, men licensmodellen, integrationsarbejdet eller dokumentationskvaliteten gør det til en langsom mølle.
IP og licenserings tjekliste:
• Protokolstakke: PCIe, Ethernet MAC/PCS, JESD204, DDR-controllere og eventuelle nicheinterfaces, du er afhængig af
• Licensbetingelser: node-låst vs flydende, funktionsudvidelser, build-server/CI-implikationer og eventuelle runtime- eller distributionsbegrænsninger
• Reference-designs: baneantal, klokkeplan, reset-sekvensering, DMA-arkitektur og om det matcher dine systemgrænser
• Supporthorisont: langsigtede vedligeholdelsesforventninger, patch-hyppighed og hvordan problemer prioriteres
Et subtilt punkt, som teamene lærer på den hårde måde: tilgængelig IP er ikke det samme som drop-in IP. Laboratoriedemonstrationer kan skjule det integrationsarbejde, der er nødvendigt for at nå dine latenser, buffer- og klokkemål. At planlægge tid til validering og favorisere IP med direkte dokumentation og kendt gode eksempler reducerer ofte stressniveauet senere, selvom den indledende evaluering virker langsommere.
Board-økosystem, opstartsrisk og komforten ved kendte gode platforme
FPGA-valg er knyttet til board-realisme. Under opstart forsvinder tiden ofte ind i platformusikkerhed snarere end RTL: en forsinket klokkespecifikation, en reset-afhængighed, der ikke var åbenlys, eller en transceiverkanal, der kun er marginal ved bestemte temperaturer.
Board- og platformtjekliste
• Evaluationsboards og referenceplatforme: tilgængelighed, revisionsstabilitet og om designet er vidt anvendt i praksis
• Strømforsyningsvejledning: PDN-mål, decoupling-tilgang, forventninger til rails-sekvensering og tolerance-stak-antagelser
• Højhastighedslayout-referencer: transceiver-routing vejledning, compliance-noter og dokumenterede stack-ups
• Debug-adgang: JTAG-stabilitet, boot/config-tilstande, konfigurations-flash-understøttelse og synlighed i rails/klokker
• Supportresponsivitet: leverandørkanaler, samfundets signal-til-støj-forhold og svartid for værktøjs/IP-problemer
At bruge en bredt adopteret platform med dokumenterede reference-designs kan gøre systemopstart mere struktureret og forudsigeligt. Denne tilgang hjælper fejlfindingsprocessen med at bevæge sig fra bred usikkerhed til trin-for-trin målbar verifikation, hvilket forbedrer udviklingseffektiviteten.
Timing-lukning
Timing-lukning er, hvor forskelle mellem leverandører bliver håndgribelige, især når udnyttelsen stiger, og flere klokkedomæner interagerer. På dette stadium kan designfremdrift enten forblive stabil og forudsigelig eller blive vanskelig, når små ændringer skaber store timingvariationer.
• Congestion-skalering: hvordan routingpres medfører, at udnyttelsen stiger, og hvor det begynder at stige dramatisk
• Fmax forudsigelighed: hvor ofte moderate begrænsninger bringer dig tæt på, kontra når der kræves tung manuel tuning
• Rapportkvalitet: om timingrapporter peger på handlingsbare rettelser, ikke bare lange overtrædelseslister
• Robusthed: adfærd på tværs af PVT-variation og på tværs af implementeringsfrø
Det er generelt mere sikkert at antage, at lukkeindsatsen vokser ikke-lineært med tætheden. Forbi en bestemt tærskel kan en mindre RTL-justering ændre slack fra sund til skrøbelig. Arkitektonisk slack, pipelining, selektiv floorplanning og valg af en enhed med plads til at trække vejret, slår ofte heroisk constraint-tuning, som ingen nyder at vedligeholde.
Sammenlign den præcise del
Specifikationer ændrer sig på tværs af generationer og inden for en enkelt familie. To dele med lignende navne kan opføre sig forskelligt nok til at forstyrre en plan, især når emballage, hastighedsklassificering og værktøjets modenhed kommer ind i billedet.
• Hastighedsklassificering: opnåelig Fmax, transceiver-marginadfærd og forskelle i timing-modeller
• Pakke: I/O-antal, bankplacering, SI-påvirkning, termisk adfærd og samlingsbegrænsninger
• SKU-funktionsgrænser: deaktiverede blokke, reduceret transceiverkapacitet, hukommelsesforhold eller protokolbegrænsninger på visse varianter
• Værktøjsmodenhed: enhedssupportniveau, udgivelseshyppighed og om dit team kan standardisere på en stabil værktøjsversion
Praktisk sammenligningsmetode:
• Leverandørens timing-modeller kortlagt til dine faktiske klokker og interfaces
• Strømestimering ved brug af realistiske toggle-hastigheder, duty cycles og transceiver-indstillinger
• Pinout/bankbegrænsninger tilpasset dine boardkrav og connector-kort
• Værktøjsversioner, din organisation kan leve med i produktets livscyklus (inklusive CI)
En beslutningsramme, der har en tendens til at holde, når tingene bliver stressende
Når tidsplanpresserne stiger, hjælper en ramme, der er baseret på målinger, med at undgå fortrydelsesdrevne skift. Det hjælper også teamet med at føle sig mere sikkert, fordi beslutninger har et papirspor knyttet til observerede resultater frem for optimisme.
Balanceret udvælgelsesrækkefølge:
1) Lås målbare krav: ressourcer, I/O, hukommelse, latency og strøm/termisk budget.
2) Prototype det hårdeste subsystem på hver kandidat: timingadfærd + debugarbejdsgang + build/CI-loop.
3) Vurder IP-modenhed og licensering i forhold til din integrationsplan, ikke marketingresuméer.
4) Vælg den mulighed med headroom og den mest forudsigelige iterationssløjfe, frem for den der lige netop klarer minimumskravene.
Hovedpunktet er, at den bedste FPGA sjældent er den med de mest spektakulære overskriftsnumre. Teams bevæger sig normalt hurtigere, og med mindre tvivl, når platformen understøtter stabil konvergens, gentagelige builds og vedligeholdelsesvenlige løsninger gennem produktets livscyklus.
Kernen værktøjslinje

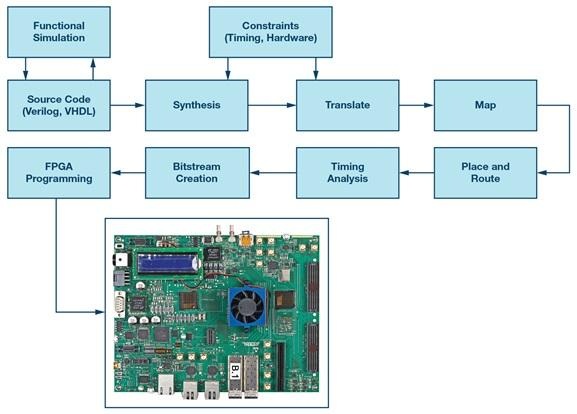
Vivados rolle i FPGA-arbejdsgangen
Vivado har tendens til at blive det operationelle knudepunkt i et Xilinx FPGA-projekt, ikke fordi det er glamourøst, men fordi det er her, hver antagelse til sidst testes mod værktøjsrealiteten. Det indtager HDL og begrænsninger, producerer en netliste, kører placering og routing samtidig med at det balancerer timing og fysiske designregler, og genererer derefter en bitstream, der programmerer enheden.
En praktisk måde at forstå Vivado på er at se det som to sammenkoblede systemer: et RTL-til-netliste konverteringssystem og en fysisk implementeringsoptimerer. Dette forklarer, hvorfor logisk korrekt RTL stadig kan producere ustabile eller inkonsekvente resultater, når begrænsningerne er ufuldstændige, klokkeslætsdefinitioner er unøjagtige, eller designstrukturen skaber routing- og timingvanskeligheder.
De fleste projekter følger en velkendt pipeline, selv når detaljerne varierer afhængigt af enhedsfamilie og flowstil.
• Syntese: oversætter RTL til en gatestruktur-repræsentation og udleder enhedsspecifikke strukturer.
• Implementering: udfører placering, routing og timing-drevet optimering under fysiske begrænsninger.
• Bitstreamgenerering: udsender konfigurationsbilledet og krydskontrollerer det implementerede resultat mod begrænsninger og værktøjsregler.
En tidsplan tenderer til at blive anspændt, ikke når en bitstream kun produceres én gang, men når teamet har brug for, at bitstreamen opfører sig som en pålidelig output: lignende resultater ved genopbygninger, timingmarginer, der overlever ved den ønskede hastighedsklasse, og stabilitet når små RTL-redigeringer foretages for funktionelle rettelser. Det er her, det bygget i går stopper med at være beroligende.
Teams, der bevæger sig hurtigere over tid, stopper typisk med at behandle rapporter som papirarbejde og begynder at behandle dem som ingeniørbeviser. Når byggeartefakterne samles konsekvent, bliver designpræsentationer mindre følelsesladede og mere konkrete, hvilket er en lettelse, når fristerne nærmer sig.
• Syntese/implementeringsrapporter: udnyttelse, udledte primitive, advarsler og strukturelle resuméer.
• Timingoutputs: WNS/TNS, mislykkedes endpoints, detaljerede stier, og clock-interaktionsresuméer.
• XDC-begrænsninger: klokker, I/O-regler, undtagelser og fysiske pin- tildelinger.
• Implementerede checkpoints (DCP): reproducerbare snapshots, der understøtter hurtig iteration og kontrollerede eksperimenter.
Et mønster, der viser sig i det virkelige arbejde, er, at et ryddeligt, internt konsekvent rapporteringssæt ofte forudsiger glattere fremgang end et enkelt grønt "BESTÅET" banner. Banneret kan skjule skrøbelighed; rapporterne gør som regel ikke.
Installation og opsætningsmiljø
En opsætning, der blot lancerer GUI'en, er let at fejre og let at fortryde senere. De opsætninger, som teamene har tillid til, er kedelige på den gode måde: de opfører sig ens under automatisering, de er konsistente på tværs af maskiner, og de overrasker dig ikke efter en værktøjsopdatering.
Vælg Vivado ML-udgaven, der matcher dine enhedsmål, og aktiver derefter kun de enhedsfamilier, du faktisk planlægger at bygge. Dette skærer ned på diskbrugen og indekseringstiden, og det reducerer også chancerne for utilsigtede tværfamiliekonfigurationsfejl, der kan spilde en eftermiddag.
I udviklingsteams med flere boards hjælper opretholdelsen af en defineret liste over understøttede enheder for hvert projekt med at holde udviklingen mere kontrolleret og ensartet end at stole på, hvilke værktøjer eller dele der tilfældigvis er installeret.
Vivado-udgange kan ændre sig på tværs af versioner, fordi placerings-, routing- og timingalgoritmer udvikler sig, og fejl bliver rettet (eller erstattet med forskellige fejl). Mange teams får roligere builds ved at fastlåse én værktøjsversion pr. udgivelsesgren og opgradere i planlagte trin fremfor at drive kontinuerligt.
Når de prøver en nyere version, sammenligner teams ofte de praktiske signaler for værktøjets sundhed, før de adopterer det som en ny baseline: timingmargener, udnyttelsesændringer, advarselsdeltaer og eventuelle nye begrænsningsdækningbeskeder. Den tid, der bruges på at lave den sammenligning, er normalt lettere end at argumentere sent i cyklussen om, hvorvidt timingen pludselig er blevet værre uden grund.
For kommandolinjeopbygninger, CI-systemer og delte bygningsservere, skal udviklingsmiljøet opføre sig konsekvent på tværs af alle systemer i stedet for at afhænge af individuelle maskinkonfigurationer.
• Indstillingsscripts: sources de rigtige værktøjsindstillinger, så stier, biblioteker og runtime-afhængigheder løses konsekvent.
• Tcl-drevne flows: foretræk scriptede opbygninger for gentagelige kørsel, ensartet rapportering og CI-integration.
• Bygningsgrænsefladedisciplin: hold indgange og udgange stabile, så ændringer er tilsigtede og gennemgåelige.
En almindelig udviklingsarbejdsgang er først at afslutte en stabil GUI-opbygning for at bekræfte designet, og derefter overgå til et Tcl-baseret flow, så opbygningsprocessen ikke længere afhænger af GUI-indstillinger, cachede data eller forskelle mellem udviklingsmaskiner.
Rapporterne, du vil læse som diagnostik
De fleste af de designmissede øjeblikke er ikke mystiske i lang tid, hvis rapporterne læses som en historie om, hvad værktøjet troede. Advarsler, begrænsningsdækning og timingstier har en tendens til at dokumentere fejlovergangen i klart lys, selvom det ikke altid er i den mest venlige rækkefølge.
Teams forbedrer sig hurtigst, når de behandler Vivado-udgange som en daglig feedback-loop snarere end noget, du kun åbner, når opbygningen går i stykker.
Disse rapporter er ofte det første sted, hvor intentioner afdækkes, og det kan være mærkeligt beroligende: i det mindste er problemet konkret.
• Ressourceudnyttelse: LUT, FF, BRAM, DSP, URAM versus enhedens grænser og overskud.
• Inferencechecks: uventede RAM-stile, manglende DSP-inference, overraskende primitive kortlægning.
• Strukturelle røde flag: høj-fanout-net, bred muxing, lange kombinationelle kæder.
• Advarsler: latch inference, ufuldstændig følsomhedshåndtering, ikke-tilsluttet eller trimmede logik.
Latch inference og utilsigtede lange kombinationelle stier viser sig ofte i praksis. Værktøjet implementerer dem uden klage, og det kan føles vildledende, når timingen senere nægter at samarbejde på måder, der ser tilfældige ud, indtil stireferaterne læses.
Timinglukning bliver mindre stressende, når teamet ved, hvad værktøjet optimerer, og hvorfor det vælger visse kompromiser.
• Slack-signaler: WNS som den værste enkelte overtrædelse; TNS som den samlede spredning af overtrædelser.
• Stibreakdown: hvor forsinkelse akkumuleres (logikdybde, routing, clocking eller begrænsningsantagelser).
• Klokmodellerings: om stier analyseres som tilsigtede, overset eller grupperet forkert.
En nuanceret læring, som erfarne teams internaliserer, er, at timing-smerte ofte først er et begrænsningsmodelleringproblem og et RTL-problem som nummer to. Når klokmodellen er forkert, kan det tage dage at optimere de forkerte endepunkter og stadig føle, at værktøjet ikke lytter.
Begrænsningshuller er en gentagen overtræder, delvis fordi de ikke altid ser dramatiske ud, indtil projektet er langt fremme.
• Klokdefinitionshuller: manglende eller forkerte primære klokker.
• Genererede klokhuller: delte/multiplicerede/fremførte klokker, der ikke er deklareret, hvilket tvinger værktøjet til at gætte.
• I/O definitionshuller: manglende I/O-begrænsninger, der fører til optimistiske antagelser og senere overraskelser på brædt-niveau.
• Undtagelsesmisbrug: manglende undtagelser eller undtagelser, der er for brede til at være pålidelige.
En pragmatisk vane er at behandle XDC som en levende specifikation i stedet for en patchfil. Når undtagelser introduceres, har teams, der sover bedre, tendens til at holde dem snævre, forklarede og knyttet til et reelt timingforhold, i stedet for at bruge dem til at dæmpe overtrædelser, der fortjener granskning.
XDC-begrænsningsstrategi
XDC-filen er, hvor designintentionen tvinges til at blive eksplicit. Når det er let forkert, kan den resulterende timingadfærd se kaotisk ud, selvom værktøjet er helt deterministisk.
Definer klokker eksplicit, så verificer, at værktøjet har udbredt dem, som du forventede. Klokmodelproblemer er ofte lettere at rette end dybere arkitektoniske timingproblemer, hvilket gør dem enklere at løse under timinganalyse og debugging.
• Primære klokker: defineret fra pins eller fra MMCM/PLL-udgange.
• Genererede klokker: defineret for delte, multiplicerede eller fremførte domæner.
• Asynkrone forhold: erklæret via klokgrupper eller eksplicitte forhold.
På rigtige brædder kan en savnet genereret klok producere et vildledende timingbillede, der brænder dage, især når værktøjet optimerer mod endepunkter, der aldrig var ment at blive analyseret sammen.
I/O begrænsninger former de elektriske og tidsmæssige antagelser, som værktøjet bruger, og det kan stille og roligt bestemme, om laboratoriets succes bliver til "systemsucces."
• Elektriske standarder: I/O standarder og spændinger tilpasset til printplade design.
• Pinning disciplin: lås pin positioner, når mapningen er stabiliseret for at undgå udskiftning.
• Grænseflade timing: input/output forsinkelser, der afspejler den eksterne enhed, ikke værktøjets standardindstillinger.
En velkendt skuffelse i den sene fase er: Den opfyldte tidskrav i bygningen, men grænsefladen fejler under reel trafik. Dette resultat spores ofte tilbage til standard I/O antagelser, der aldrig blev opdateret for at matche printpladen og den eksterne enheds tidsbudget.
Undtagelser kan præcisere hensigten, og de kan også skabe en skrøbelig illusion af fremskridt, hvis de overlever deres oprindelige retfærdiggørelse.
• Falske veje: bruges kun, når vejen faktisk ikke er en del af funktionel timing.
• Multicykel veje: bruges kun, når optagelsesforholdet virkelig strækker sig over flere cykler og er dokumenteret.
• Undtagelseshygiejne: hold sættet lille, gennemgå det efter større RTL/pipeline ændringer, og pensionér gamle poster.
Nogle af de dyreste timingfejl kommer fra undtagelser, der engang var nøjagtige, og derefter stille blev unøjagtige efter en pipelineændring. Værktøjet vil overholde uden klage, hvilket netop gør denne fejlsituation så ubehagelig.
Typiske fejlmønstre og hvordan man løser dem effektivt
Visse problemer gentager sig på tværs af projekter, uanset om applikationen er netværk, vision, kontrol eller acceleration. At genkende mønsteret tidligt har tendens til at reducere den følelsesmæssige belastning ved fejlfinding, fordi teamet kan gå fra "hvorfor sker dette?" til "hvilken playbook gælder?"
Denne situation føles ofte som om værktøjet er stædigt, men roden af problemet er normalt sporbar.
• Kombinationsdybde: lange veje forårsaget af manglende eller utilstrækkelig pipeline.
• Fanout pres: højfanout kontrolnet, der drager fordel af replikation, buffer eller omstrukturering.
• Begrænsningsmodellering: klokdefinitions eller relationer, der miskarakteriserer, hvad der bør analyseres.
En sekvens, der har tendens til at fungere godt, er: validere timingmodellen (klokker og relationer), fokusere på de værst fejlfunktionerende endpoints først, og derefter udvide til arkitektoniske ændringer, kun hvis stiernes beviser understøtter det.
Dette er en af de mere demoraliserende oplevelser inden for FPGA-arbejde, mest fordi det føles som om, at virkeligheden er uretfærdig. Normalt er det bare, at simuleringen ikke teste de samme fejlsituationer.
• CDC/reset adfærd: reset sekvensering og klokdomæneoverskridelse, som simuleringen sjældent udøver realistisk.
• I/O antagelser: ubegrænsede eller misbegrænsede I/O, der producerer marginale reelle grænseflader.
• Initialiseringsadfærd: afhængighed af indledende værdier, der ikke kortlægger pænt til enhedens opstartsadfærd.
Teams, der får en mere stabil tilgang, medtager CDC og reset strategi tidligt i design diskussionen, og behandler dem som en del af designarkitekturen snarere end en oprydningsfase efter den "virkelige logik" er færdig.
Dette problem er almindeligt, fordi placering og rute reagerer skarpt på ændringer i nettets struktur, selv når den funktionelle ændring virker lille.
• Netlist følsomhed: små refaktoreringer kan ændre pakning, placering beslutninger og ruteoverbelastning.
• Begrænsningsdrift: små XDC ændringer (eller manglende dækning) kan forstærke timing variation.
• Afbødningsvaner: trinvis implementering, selektiv hierarkibevaring, og stabile begrænsninger.
Når teams vedtager disse afbødningsvaner, føles iterationen ofte mere forudsigelig, hvilket reducerer fristelsen til at fryse designet for tidligt af frygt for at bryde timing igen.
Licensovervejelser
Licenser bliver ofte et emne, når et projekt støder på enhedsdækningsgrænser, eller når avancerede funktioner er nødvendige for en bestemt arbejdsgang.
• Standard: tilpasset ofte indgangs- og mellemliggende læringsplader og baseline flows.
• Enterprise: tilpasset ofte bredere enhedsunderstøttelse og avancerede funktioner.
For teams er flydende licenser understøttet af en licensserver ofte lettere at skalere end node-låste licenser, især når builds kører på delte maskiner, dedikerede byggeserver eller CI-løbere. Mange teams foretrækker at tilpasse licensering med enhedsroadmap tidligere end senere, fordi licensoverraskelser har en tendens til at dukke op, når det allerede er dyrt og politisk svært at skifte enheder.
En konsekvent ingeniørloop har tendens til at forudsige mere stabil fremgang end enhver enkelt smart optimering: hold begrænsningerne i overensstemmelse med virkeligheden, læs rapporter rutinemæssigt (selv når du hellere vil lade være), fix årsagerne til problemer i stedet for at dæmpe symptomer, og hold builds reproducerbare. Når denne loop er etableret, føles Vivado mindre som en sort boks og mere som et instrumentbræt, og timinglukning skifter fra sidste-øjebliks pres til noget, som teamet kan styre bevidst.
Xilinx Portfolio and Ecosystem

Valg blandt Xilinx-enheder går ofte mere glat, når udgangspunktet er den omkringliggende integration (processorer, hukommelsesgrænseflader, opstartssti og kortniveau afhængigheder), ikke kun en sammenligning af rå LUT-totaler. Denne indramning matcher som regel, hvordan reale tidsplaner og reale risici dukker op.
En diskret FPGA passer ofte, når teamet ønsker fuldt ejerskab af boardsarkitekturen, og arbejdsbyrden læner sig mod deterministisk hardwareadfærd med minimal softwareoverflade. En Zynq-klasse SoC passer, når designet drager fordel af en CPU, der sidder tæt på accelerationslogik, så kontrol og datapath kan udvikle sig sammen uden at gøre boardet til en multi-chip forhandling. En Kria SOM-stil modul passer, når planen er at bevæge sig hurtigt og begrænse usikkerheden ved boardopstart ved at behandle beregning, hukommelse og boot-lagring som en forudgodkendt byggesten.
Diskrete FPGA passer til:
• maksimal board-design kontrol
• deterministiske pipelines med begrænset softwareafhængighed
Zynq SoC passer til:
• tæt CPU+accelerator sammenkobling
• samlet beregning/kontrol på én enhed
• iterativ HW/SW udvikling
Kria SOM passer til:
• kortere tid til produkt
• reduceret board-niveau eksponering ved at bruge et valideret beregningssystem
Almindelige FPGAs lander ofte godt, når problemet drives af timinglukningspres, usædvanlige I/O behov eller streaming pipelines, der fungerer bedst som fastfunktionshardware. Forudsigelig latenstid og strukturerede datapaths forbedrer ofte kontrol, verifikation og fejlfinding, især når arkitekturen forbliver godt organiseret.
Standealone enheder dukker ofte op i:
• sensorinterfacing
• motorstyring
• moderat hastighedspakke behandling
• protokolbro
I felten er en tilbagevendende kilde til frustration ikke RTL'en selv, men de omkringliggende boardforpligtelser, der kommer stille og derefter dominerer den kritiske sti. Strømforsyningslinjer, konfiguration og boot-strategi, clockgenerering, ekstern hukommelseslayout (når tilstede), og debuggingadgang kan blive til de begrænsninger, der former hele produktet. En praktisk tommelfingerregel er, at jo enklere historien om ekstern hukommelse er, og jo færre højhastighedstransceivere der er involveret, desto mere tilfredsstillende bliver den standalone FPGA-oplevelse. Så snart ekstern DDR og multi-trins boot flows bliver uundgåelige, begynder den integrerede tiltrækning af en SoC eller et modul at føles mindre som en funktion og mere som en lettelse.
Omkostningsoptimerede familier sigter generelt mod en målt blanding af LUTs, BRAM og DSP under begrænsede strømbudgetter. De fremstår ofte i produkter, hvor ingeniørteamet ønsker respektabel kapacitet uden at betale board- og termisk skat, som kommer med ekstreme grænseflader.
Almindelige landingszoner inkluderer:
• indbygget kontrol
• mellemhastigheds I/O aggregation
• moderat hastighedssignalbehandling
Fordelen er ikke kun enhedspris; teams værdsætter ofte, at disse dele gør det lettere at forblive indenfor termiske grænser uden at ty til aggressiv køling, og de kan holde PCB fra at eskalere til et højhastigheds layoutprojekt. Samtidig lærer feltopbygninger ofte en lidt ubehagelig lektie: en lavere omkostningsenhed kan udløse højere samlede udgifter, hvis det tvinger til kompromiser i sent design. Når timingmarginen er tynd, kan små justeringer, en ændring i I/O-standard, et clock-routing tweak, et floorplan shift, skabe bølger i verifikationsforstyrrelser og tidsplanangst. For disse enheder sparer teamene ofte tid ved tidligt at fastlægge clock-domain planlægning, CDC-strategi og reset-adfærd i stedet for at håbe, at sene mikrooptimeringer vil redde planen.
Zynq SoCs
Zynq-enheder kombinerer ARM-behandling med programmerbar logik, hvilket lader designet opdele i kontrolplane-software og dataplane-acceleration på en måde, der føles naturlig for mange produkthold. Dette gør mere end at forbedre bekvemmeligheden; det omformer arbejdsflowet. Hold kan starte med en software-første reference for funktionel tillid, og derefter migrere varme stier ind i hardware, efterhånden som throughput- og laten krævninger bliver mindre forhandlingsbare.
I implementeringer, der ældes godt, "erstatter" CPU'en sjældent hardware, den har tendens til at stabilisere produktet. Processoren ender ofte med at håndtere konfiguration, telemetri, feltopgraderinger, sikkerhedspolitik og edge-forbindelse, mens stoffet kører deterministiske pipelines. Den adskillelse kan være følelsesmæssigt betryggende for vedligeholdere: software absorberer ændringer, hardware forbliver stabil, og udgivelser føles mindre som et væddemål.
CPU'en bærer typisk:
• konfiguration
• telemetri
• opgraderinger
• sikkerhedspolitik
• edge-forbindelse
Stoffet bærer typisk:
• deterministiske streaming-pipelines
• stabile accelerators
• latenfølsomme datapather
Efterhånden som beregningsdensiteten stiger, og interfaces bliver mere krævende, reducerer Zynq UltraScale+-stil dele boards og systemkompleksitet ved at trække CPU-kerner, DDR-controllere og høj-båndbredde interconnection tættere på stoffet. Dette bliver attraktivt i designs, der har brug for både realtidsdeterminisme og et kapabelt softwaremiljø, især når arbejdsbyrden er en blanding snarere end en enkelt ren kerne.
Hyppige brugssager inkluderer:
• edge-analyse
• multi-sensor fusion
• blandede realtid plus AI-pipelines
Et detalje, som erfarne teams lærer at respektere, er, at "mere stof" ikke automatisk bliver til "mere leveret ydeevne." Projekter løber ofte ind i hukommelsesbåndbredde-loft, før de løber tør for DSP'er eller LUT'er. Designs, der beslutter sig for DMA-topologi, bufferstrategi og cache-kohærens-forventninger tidligt, har tendens til at nå stabil ydeevne med mindre thrash end designs, der udsætter databevægelsesbeslutninger indtil sent i integrationen.
Partitionering handler sjældent om, hvorvidt noget kunne accelere, det handler mere om, hvorvidt acceleration betaler sig i forhold til verifikationsindsats, driver- og runtime-kompleksitet, og hvor ofte logikken forventes at ændre sig. Teams føler ofte en tovtrækning her: at presse for meget ind i hardware kan forsinke iteration, mens at efterlade for meget på CPU'en kan efterlade throughput-mål næsten vedvarende i nærheden af målet.
Arbejdsbelastninger, der ofte forbliver på CPU'en længere end forventet, inkluderer:
• hurtigt skiftende logik
• kompleks parsing-tung adfærd
• funktioner med hurtige iterationscyklusser
Arbejdsbelastninger, der ofte belønner tidlig stofacceleration, inkluderer:
• stabile algoritmer
• beregningsdense kerner
• stream-venlige datapathere
Et pragmatisk mønster er at begynde med et lille, end-to-end udsnit, ofte en simpel DMA-loopback plus en minimal accelerator, før man bygger det fulde funktionssæt. Den begrænsede prototype har tendens til at afdække integrationsproblemer, som ellers ankommer sent og dyrt: afbrydelsesadfærd, bufferjustering, cachevedligeholdelsesomkostninger og throughputlofter, der kun vises under vedvarende belastning.
Kria SOMs og modul-stil platforme
Kria SOMs pakker beregning, hukommelse og opstartslager i et klar subsystem, hvilket skifter indsatsen væk fra board-opstart og hen imod applikationsengineering. Teams kan godt lide denne tilgang, fordi den indeholder usikkerhed: signalintegritet, DDR-routing, strømsekvensering og opstartspålidelighed er allerede valideret, hvilket kan få tidlige demoer til at føles mindre skrøbelige og planlægning til at føles mindre spekulativ.
Tilgangen har tendens til at fungere særligt godt, når differentiering ligger i algoritmer, I/O-topologi og implementeringspålidelighed frem for i et specialfremstillet beregningsboard. Det kan også reducere krydsteamfriktion: hardware, firmware og anvendelsesarbejde kan bevæge sig parallelt med færre "blokeret af opsætning" øjeblikke.
Valideret SOM-integration dækker typisk:
• signalintegritet
• DDR-routing
• strømsekvensering
• opstartspålidelighed
Teams kan omfokusere indsatsen på:
• carrier-board differentiering
• firmwareintegration
• applikationsadfærd
• implementeringshærdning
En SOM bærer ofte højere enhedsomkostninger end et fuldt tilpasset board, men de totale programomkostninger kan stadig falde, når tidsplanerne er tætte eller fremstillingsudbytte-risikoen er ubehagelig. Den mindre åbenlyse gevinst er livscykluspålidelighed: med et modul kan beregning nogle gange behandles som et udskifteligt element på tværs af produktvarianter, hvilket reducerer redesignsvingninger, når kravene ændrer sig undervejs.
Det mest beroligende skridt er tidligt at validere, at SOM'ens termiske hovedplads, I/O-eksponering og hukommelsesbåndbredde faktisk matcher den tiltænkte arbejdsbelastning, i stedet for at stole på en spec-sheet læsning. Hvis applikationen ender med at være båndbreddebegrænset, føles tuning i sent stadium ofte som at presse på en låst dør, mismatchen mellem acceleratorens efterspørgsel og modulens hukommelsessubsystem dominerer simpelthen.
Tidlige justeringskontroller inkluderer:
• termisk omslag
• eksponeret I/O
• vedvarende hukommelsesbåndbredde versus arbejdsbelastningskrav
AI-implementering i økosystemet
Vitis AI hjælper med at konvertere trænede modeller til FPGA-baserede inferensdesign ved at bruge lavere præcisionsformater, ofte INT8, og kompilere dem til DPU-stil arkitekturer. Dette bekræfter hurtigt, om en model kan fungere på FPGA-platformen. Den faktiske ydeevne afhænger dog ofte stærkt af det omgivende systemdesign, især databevægelse og hukommelseshåndtering.
End-to-end gennemstrømning styres typisk af, hvor konsekvent systemet kan fodre DPU'en. Batching-strategi, tensor-layout, DMA-planlægning, double-buffering og hukommelsesplacering beslutter ofte de leverede FPS mere end beregningens overskrift. Teams, der behandler DPU'en som en stabil streaming-forbruger med omhyggeligt iscenesatte buffere, har tendens til at undgå den almindelige skuffelse over imponerende teoretisk TOPS, men skuffende systemniveau-resultater.
Ydeevneformende knapper omfatter typisk:
• batching-strategi
• tensor-layout
• DMA-planlægning
• double-buffering
• hukommelsesplacering
I udrulninger kan mindre implementeringsvalg samlet set have effekter, der kan være svære at forudsige fra laboratoriemikrobænkmarkeringer. Forkerte buffere kan stille og roligt reducere effektiv båndbredde. Overdreven cachevedligeholdelse kan optage CPU-tid og skabe jitter. Kopi-tunge pipelines kan slette meget af den fordel, der opnås fra kvantisering. En jordnær tilgang er at måle båndbredde og latens ved hver grænse og derefter koncentrere indsatsen om den grænse, der aktuelt er strammest.
Nyttige målegrænser omfatter:
• sensor til DDR
• DDR til accelerator
• accelerator til efterbehandling
En nyttig mental model er at betragte AI-pipelinen som et begrænset flow-netværk. Med den ramme bliver valg af enhed mindre om at jagte det største beregningsnummer og mere om at vælge den mulighed, der løsner den dominerende flaskehals og holder pipeline-adhæren forudsigelig.
Økosystem og muliggørelse
Xilinx-økosystemet strækker sig ud over silikonet til den omkringliggende muliggørelse, der holder teamene i gang: værktøjs kæder, IP, referencedesign, partnerboards og træningsressourcer. I akademiske omgivelser værdsættes University Program ofte, fordi det reducerer tilbagevendende opsætningsbesvær, værktøjsadgang, tilgængelighed af boards og laboratorie struktur, så tidlig fremgang mindre sandsynligt stopper på miljøproblemer snarere end på at lære den faktiske ingeniørkunst.
Økosystemkomponenter omfatter:
• værktøjs kæder (Vivado, Vitis)
• IP-kataloger
• referencedesign
• partnerboards
• træningsprogrammer
• University Program-ressourcer
Når onboarding-friktionen er reduceret, kan lærende bruge deres energi på de vaner, der direkte oversættes til professionelt arbejde: timing-closure-rutiner, pipelining-disciplin, verifikationsstrategi og hardware/software co-design-dømmekraft. Disse færdigheder viser tendens til at vise deres værdi under integration, når resultater formes mere af iterationshastighed og systemkohæsion end af en isoleret kernebænkmark.
Overførbare færdigheder omfatter:
• timing-closure-vaner
• pipelining-disciplin
• verifikationsstrategi
• hardware/software co-design
Et udvalgsprincip, der forbliver konsekvent på tværs af sortimentet
En pålidelig urvalstilgang starter fra systembegrænsninger frem for markedsføringsniveauer. Teams får generelt klarere beslutninger, når de skriver driftsmålene og projektrealiteterne ned fra starten, og derefter vælger det integrationsniveau, FPGA, Zynq SoC eller SOM, der reducerer de største kilder til usikkerhed for deres specifikke program. Dette producerer tendens til at føre til valg, der føles bedre måneder senere, når integration og iterationshastighed betyder mere end en sammenligning af dele på papir.
Begrænsninger, der skal defineres tidligt, omfatter:
• latensmål
• bæredygtige båndbreddebehov
• grænsefladekrav
• termiske grænser
• opdateringsfrekvens
• verifikationsbudget
I mange programmer er muligheden for at holde databevægelse ligetil og udviklingssløjfen stram den, der får det bedste "holdbarhed", selvom dens pris pr. enhed ikke er den mest attraktive ved første øjekast.
Konklusion
At lære Xilinx FPGA-design bliver lettere, når hvert projekt følger en stabil og gentagelig proces. Stærke resultater afhænger af rent HDL, korrekte begrænsninger, omhyggelige timingkontroller, simulering og reel hardwarevalidering. Ved at starte med enkle designs og opbygge gode fejlfinding vaner kan begyndere udvikle pålidelige FPGA-færdigheder til mere avancerede digitale systemer.
Ofte stillede spørgsmål [FAQ]
1. Hvorfor har FPGA-begyndere ofte problemer, selv når deres HDL-kode ser logisk korrekt ud i simuleringen?
Mange tidlige FPGA-problemer skyldes ikke selve RTL, men kløften mellem simulationsforudsætninger og fysisk hardwareadfærd. Simulation skjuler ofte problemer relateret til klokkegrænser, reset-timing, I/O-standarder, metastabilitet og timing-closure. Et design kan simulere perfekt, mens det stadig fejler på hardware, fordi FPGA-værktøjerne tolker klokker forskelligt, begrænsninger er ufuldstændige, eller asynkrone input håndteres forkert.
2. Hvorfor betragtes timingbegrænsninger som en kernekomponent i FPGA-design i stedet for et afsluttende optimeringsskridt?
Timingbegrænsninger definerer, hvordan FPGA-værktøjerne tolker klokker, I/O-timingforhold, genererede klokker og asynkrone domæner. Uden nøjagtige begrænsninger kan Vivado optimere designet ved hjælp af forkerte forudsætninger, hvilket fører til vildledende timingrapporter og ustabil hardwareadfærd. Mange FPGA-fejl opstår, selv når logikken i sig selv er korrekt, fordi klokker ikke blev erklæret korrekt, I/O-timing blev ignoreret, eller undtagelser blev anvendt for bredt. I praksis fungerer begrænsninger som en formel beskrivelse af designintentionen, hvilket gør det muligt for værktøjerne at bygge hardware, der matcher faktisk elektrisk adfærd.
3. Hvorfor kræver FPGA-fejlretning ofte både simulation og on-chip værktøjer som ILA?
Simulation er meget effektiv til at opdage funktionsfejl, men den kan ikke fuldt ud reproducere virkelige hardwareeffekter såsom jitter, asynkrone input, board-niveau forsinkelser, metastabilitet og opstartvariation. On-chip fejlretterværktøjer som den integrerede logikanalysator (ILA) giver indsigt i interne FPGA-signaler, mens systemet fungerer under reelle forhold. Dette muliggør fangst af faktiske tilstandsovergang, FIFO-adfærd, håndtryk og timingforhold direkte inde i enheden. Kombinationen af simulation med ILA-fejlretning skaber en mere fuldstændig forståelse af, hvorfor hardwaren divergerer fra den forventede adfærd.
4. Hvorfor foretrækker erfarne FPGA-ingeniører disciplinerede, gentagelige arbejdsgange frem for konstant at ændre projektopsætninger?
Gentagelige arbejdsgange reducerer usikkerhed og gør det lettere at isolere fejl. Ved at bruge den samme udviklingsplade, klokkestruktur, reset-strategi og projektskabelon kan ingeniører fokusere på den udviklede logik i stedet for gentagne gange at fejlfinde selve miljøet. FPGA-projekter involverer mange sammenkoblede variabler, herunder begrænsninger, klokke, synteseadfærd og konfiguration på board-niveau. Når for mange variabler ændrer sig samtidigt, bliver fejlfinding uforudsigelig og følelsesmæssigt udmattende. Stabile arbejdsgange forbedrer tilliden, fordi ændringer kan spores tilbage til specifikke designbeslutninger i stedet for ukendte miljøforskelle.
5. Hvorfor er FPGA-hardwaredesign fundamentalt anderledes end traditionel softwareprogrammering?
Software udfører instruktioner sekventielt, mens FPGA-hardware fungerer gennem samtidige logikstrukturer, der kører samtidig. HDL beskriver fysisk hardwareadfærd snarere end proceduremæssig udførelsesflow. Nybegyndere forventer ofte software-lignende adfærd og bliver forvirrede, når flere hardwareblokke reagerer samtidigt på den samme klokkeændring. FPGA-design lægger derfor vægt på pipelines, timingforhold, synkronisering, ressourcekortlægning og klokkesdomæneadfærd i stedet for udelukkende instruktionens rækkefølge. At forstå samtidighed er et af de vigtigste mentale skift i FPGA-ingeniørarbejde.
6. Hvorfor kan små RTL-ændringer pludselig forårsage store timing-closure problemer i FPGA-projekter?
FPGA-timingadfærd afhænger stærkt af placering, routing-kongestion, fanout, klokke-forhold og fysisk ressourceudnyttelse. Selv små RTL-modifikationer kan ændre, hvordan syntese- og routingværktøjerne kortlægger logik på tværs af enheden. En tilsyneladende uskadelig ændring kan øge routingpres, forlænge kombinationsveje eller påvirke placeringsbeslutninger på måder, der væsentligt reducerer timing-marginalen. Denne følsomhed bliver mere alvorlig, efterhånden som udnyttelsen stiger, især når design nærmer sig routing- eller klokkelimitationsgrænser.
7. Hvorfor bliver FPGA-projekter ofte begrænset af hardware-niveau realiteter i stedet for kun RTL-kompleksitet?
Efterhånden som FPGA-systemer vokser, dominerer udfordringer relateret til strømsekvensering, DDR-layout, klokke-generering, termisk adfærd, signalintegritet og transceiver-routing ofte udviklingstiden. RTL'en kan fungere korrekt, mens den omgivende hardwareinfrastruktur introducerer ustabilitet eller integrationsfejl. Ingeniører opdager ofte, at designbeslutninger for boards, reset-sekvensering og hukommelsesinterfaceadfærd former den samlede projektsucces mere end selve HDL. Dette er især sandt i højhastighedssystemer, der bruger ekstern DDR-hukommelse og SERDES-grænseflader.
8. Hvorfor vurderer mange FPGA-hold værktøjskæder lige så seriøst som FPGA-hardware i sig selv?
FPGA-værktøjskæden påvirker direkte kompileringstid, stabilitet i timing-lukning, debug-effektivitet, CI-integration og den samlede ingeniørproduktivitet. Langsomme eller inkonsekvente implementeringsresultater kan dramatisk øge iterationstid og tidsplanpres. Hold vurderer ofte syntese-kvalitet, timing-rapport klarhed, debug-instrumentering og reproducerbarhed, før de forpligter sig til en platform. I reelle udviklingsmiljøer betyder forudsigelige builds og stabil timing-lukning ofte mere end isolerede hoved-FPGA-specifikationer.
9. Hvorfor reducerer Zynq SoCs og Kria SOM-platforme integrationskompleksitet sammenlignet med stand-alone FPGAs?
Zynq SoCs kombinerer ARM-processorer og programmerbar logik inden for én enhed, hvilket forenkler kommunikationen mellem software og hardwareacceleration. Kria SOMs går videre ved at integrere hukommelse, boot-lagring, strømsekvensering og valideret hardware i en forudkvalificeret modul. Disse tilgange reducerer risici forbundet med DDR-routing, boot-pålidelighed, strømleveringsdesign og board-opstart. Som et resultat kan hold fokusere mere på applikationsadfærd og mindre på integration af lavniveau hardwareudfordringer.
10. Hvorfor afhænger succesfuld FPGA-baseret AI-implementering i høj grad af databevægelse snarere end acceleratorens ydeevne alene?
AI-acceleratorer som DPUs kan give høj teoretisk beregningsgennemstrømning, men den virkelige ydeevne bliver ofte begrænset af hukommelsesbåndbredde, DMA-planlægning, bufferhåndtering og tensorbevægnings effektivitet. Dårligt optimerede datapipelines kan sulte acceleratorer og dramatisk reducere effektiv FPS på trods af stærk beregningskapacitet. Succesfulde FPGA AI-systemer fokuserer derfor i høj grad på double-buffering, DMA-topologi, batching-strategi, hukommelsesplacering og konstant databevægelse mellem sensorer, DDR-hukommelse, acceleratorer og postbehandlingsfaser.
Relateret blog
-
Hvor mange nuller på en million, milliarder, billioner?
![Hvor mange nuller på en million, milliarder, billioner?]()
2024-07-29
Million repræsenterer 106, en let forståelig figur sammenlignet med hverdagens varer eller årlige lønninger. Milliarder, svarende til 109, begynde... -
IRLZ44N MOSFET datablad, kredsløb, ækvivalent, pinout
![IRLZ44N MOSFET datablad, kredsløb, ækvivalent, pinout]()
2024-08-28
IRLZ44N er en bredt brugt N-kanals magt MOSFET.Det er kendt for sine fremragende switching -kapaciteter, det er meget egnet til adskillige anvendelser... -
Batteritemperatur for lav, opladningen stoppede.Hvordan løser jeg det?
![Batteritemperatur for lav, opladningen stoppede.Hvordan løser jeg det?]()
2024-10-06
Problemer med opladning af mobiltelefonbatteri er almindelige, men kan styres effektivt.Temperaturen spiller en stor rolle i batterieffektiviteten, da... -
BC547 Transistor Comprehensive Guide
![BC547 Transistor Comprehensive Guide]()
2024-07-04
BC547 -transistoren bruges ofte i en række elektroniske applikationer, der spænder fra grundlæggende signalforstærkere til komplekse oscillatorkre... -
Omfattende guide til SCR (siliciumstyret ensretter)
![Omfattende guide til SCR (siliciumstyret ensretter)]()
2024-04-22
Siliciumkontrollerede ensretter (SCR) eller tyristorer spiller en central rolle inden for effektelektronik -teknologi på grund af deres ydeevne og p... -
LR621, SR621SW, 364, AG1 Batteryækvivalenter og udskiftninger
![LR621, SR621SW, 364, AG1 Batteryækvivalenter og udskiftninger]()
2024-07-15
LR621 og SR621SW -knapbatterier er udbredt i kompakte elektroniske enheder som ure, små legetøj, regnemaskiner og fjerntaster.Flere producenter prod... -
En komplet guide til multiplexere og deres rolle i digitale systemer
![En komplet guide til multiplexere og deres rolle i digitale systemer]()
2025-09-20
Multiplexere er komponenter i digitale systemer, designet til at kanalisere flere indgangssignaler til en enkelt outputlinie ved hjælp af binære log... -
Grundlæggende om op-amp-kredsløb
![Grundlæggende om op-amp-kredsløb]()
2023-12-28
I den indviklede verden af elektronik fører en rejse ind i dens mysterier, der altid er til et kalejdoskop af kredsløbskomponenter, både udsøgte o... -
Sammenligning af NMOS- og PMOS -forskelle og applikationer
![Sammenligning af NMOS- og PMOS -forskelle og applikationer]()
2024-11-15
At forstå forskellene mellem NMOS og PMOS -transistorer er vigtige for at designe effektive kredsløb.NMOS (N-type metaloxid-halvleder) og PMOS (P-ty... -
CR2450 vs CR2032 Sammenligning: Alt hvad du behøver at vide
![CR2450 vs CR2032 Sammenligning: Alt hvad du behøver at vide]()
2025-09-15
Knapbatterier som CR2450 og CR2032 strøm mange hverdagens elektronik, fra ure og fjernbetjeninger til medicinske og industrielle enheder.Selvom de er...










Hot Dele
- 06031A101JA14A
- SC505809CFUB8
- GRM1887U2A1R0CZ01D
- N80C196KC16
- LM5010AMHX
- TAP107M016SCS
- THJD685K035RJN
- PMB8818V2.4N
- CC1206JRNPO0BN181
- M306V7FGFP
- GRM0225C1E9R6CA03L
- 1N4728A
- K5L2931CAM-D770
- AD586JRZ
- MAX5404EUB
- K5L5563CAA-D770
- EGF1THE3/67A
- ACPL-330J-500E
- DS1814CR-10/TR
- 12103U271FAT9A
- STLC2500ATR
- HA13715FPEL
- SM8951AC25JP
- PCM1740E
- MAX4619ESE+T
- XC1701LPC20I
- PS21454-E
- TS5A22362DGSR
- T7L58XB-0101
- NL3280DSH-266
- 1903112-2
- 06035A130JAT2A
- CM1407-08DE
- T491D106K025AT24787622
- V24C24T100BL
- DS26324GN
- LTC2224UK
- NP3750PBC-400
- PEB20525F
- FE1.1-AQFP48A
- 6MBP50RA-O60
- ELJLC3R3MF
- MM32SPIN06PF
- SPC5604BMLQ4
- D78042AGF
- LTC2980BY#PBF
- R7F701312GAFA
- MF25 100R
- 9185646902
- 50PFR120